Redis 101
Published:
This article introduces Redis, a widely-used in-memory data store. It covers Redis basics, caching strategies, data structures, persistence mechanisms, and techniques.
1. Redis Introduction
1.1. What is Redis?
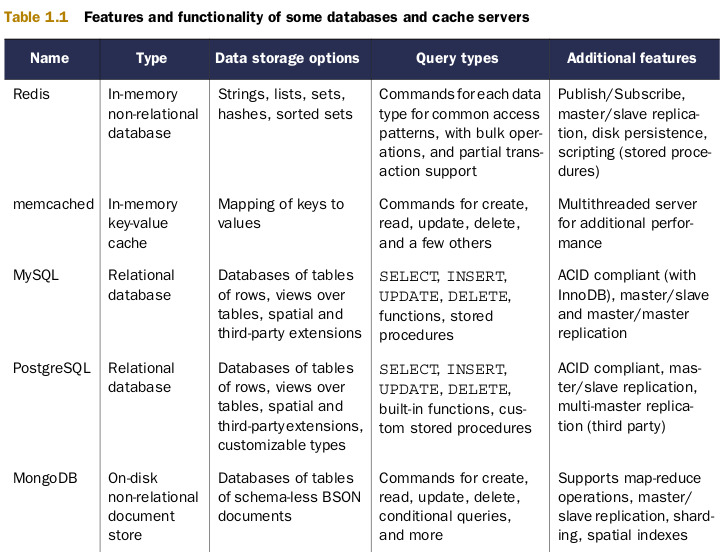
Generally, Redis is a in-memory data structure store, used as a database that stores a mapping of keys to different value types
Redis supports in-memory persistent storage on disk, replication to scale read performance, client-side sharding to scale write performance
Sharding is a method of partitioning data into difference pieces. (ex: based on IDs of keys, hashes…)
1.2. Compared to other db and software
In Redis, there are no tables, no database-defined way of relating data together
It’s not uncommon to compare Redis vs memcached.
Like memcached, Redis store a mapping of keys to values, achieve similar performance as memcached.
Redis ~ single thread execution (better performance for atomic operations), while memcached ~ multithreads
However, Redis supports the writing of its data to disk automatically, can store 4 different data structures beside plain string as memcached
⇒ Generally speaking, Redis users will choose to store data in
Redis only when the performance or functionality of Redis is necessary,
other relational or non-relational data storage for data where slower performance is acceptable, or where data is too large to fit in memory economically
1.3. Why Redis?
High performance and low latency
Redis been written in C → Optimize compiler better
Runs entirely in memory (> 1.5m ops/s with <1ms latency)
Single thread with atomic operations
Support pre build-in data structures
→ Simplify application, addressing complex functionalities within simple commands
Allows data to be processed on the database level instead of application level → reduce code complexity, bandwidth requirements, …

Compatibility
Open source and stable, used by tech-giants like GitHub,Weibo, Pinterest, Snapchat, Craigslist, Digg, StackOverflow, Flickr
Large supporting community for almost all famous programming languages (Most loved database by developer (stackoverflow))
Redis Modules: extend Redis to cover most popular use cases in a wide variety of industries (Search, json, ML, data processing, …)
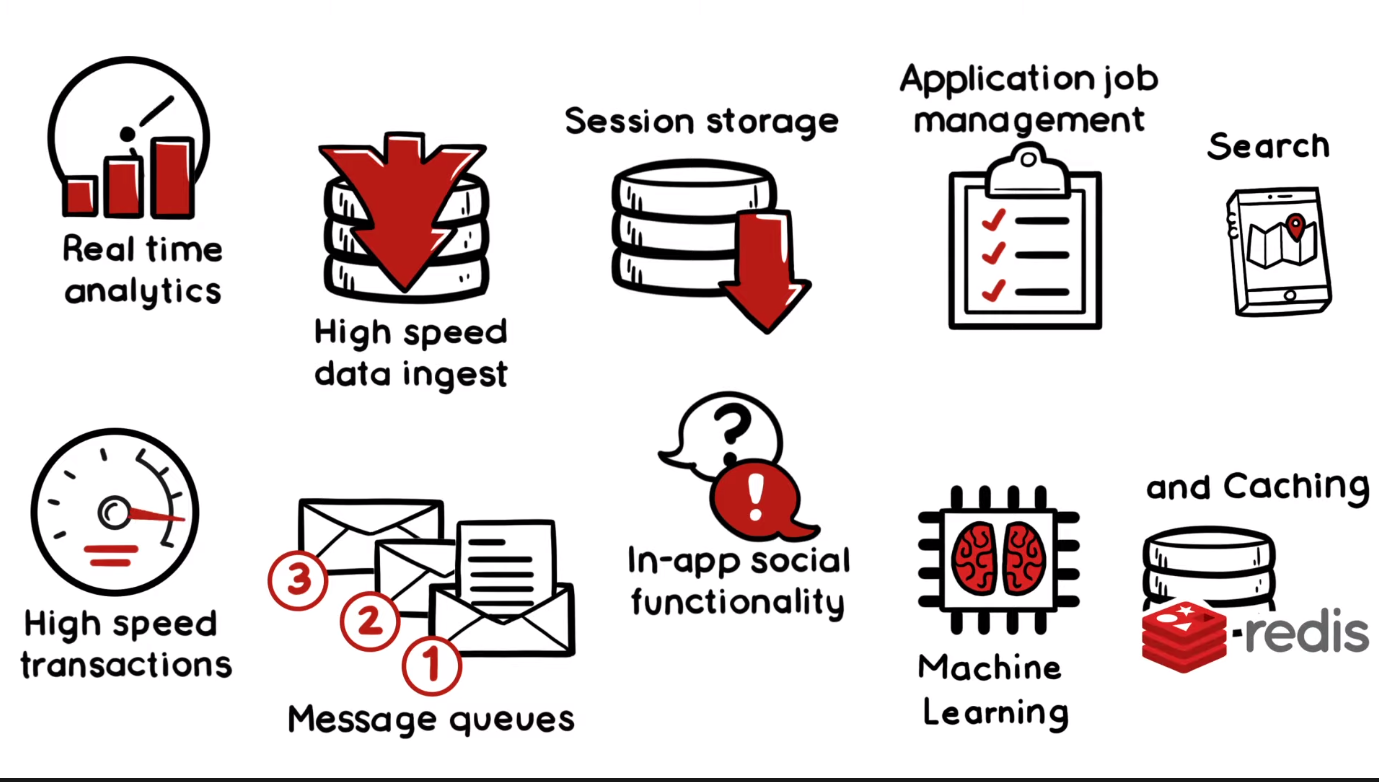
2. Redis caching Strategies
2.1. Cache aside

This is the most commonly used caching strategy. The idea is that the cache sits between the application and the data source. The application will prioritize fetching data from the cache. When data is not available in the cache, the application will retrieve it from the data source, then update the cache, so that subsequent requests can find the data in the cache.
Use Cases: This strategy is typically used for heavy data that is accessed frequently and returns results that change infrequently.
Advantages: Systems using this strategy have the ability to recover from cache failures. If the cache fails, the application can directly access the data source.
Disadvantages:
- Does not guarantee data consistency; requires an appropriate cache update strategy.
- When called for the first time, data is not in the cache => extra call to cache => needs warm-up, loading data into the cache beforehand.
2.2. Write through

The application fetches data similar to Read-Through, but when updating data, the Cache Provider will prioritize updating the cache first, then the Cache Provider will automatically update the data to the data source.
Use Cases: Combined with Read-Through to ensure data consistency.
Advantages: Ensures data consistency.
Disadvantages: Increases latency when writing data.
2. Redis data structures
2.0. Redis keys
Redis keys are a binary safe, made up of a sequence of bytes, use any binary sequence as a key (which can hold string, integers, images, files, and serializable objects in them)
Key names maximum size = 512MB; Tradeoff between Length vs Readability
Key spaces:
- Logical databases:
- Database zero: assure unique key names
- Flat key space: All key names occupies same space -> Need naming convention
- No automatic namespace (ex: bucket, collection…)
- Redis does not store empty lists, sets, sorted sets or hashes
Example: “user![]() followers”
followers”
- User: object name
- 1000: unique identifier of the instance
- Followers: composed object
Commands
KEYS (O(N) with N being the number of keys in the database)
Blocks until complete , which may ruin performance when it is executed against large databases -> Never use in production
→ Not safe for production
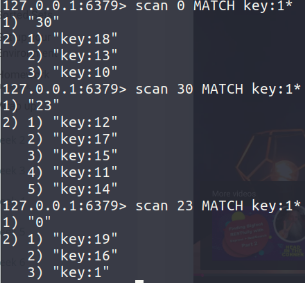
SCAN (O(1) for every call. O(N) for a complete iteration)
cursor based iterator (pointer to next iteration); terminates when redis SCAN return 0
SCAN does not provide guarantees about the number of elements returned at every iteration. Using COUNT to hint the implementation (default = 10)
invalid cursor will result in undefined behaviors but never into a crash
Drawbacks: A given element may be returned multiple times. Inconsistency elements may be returned or not: it is undefined
Redis enables automatic expiration of keys through a Time To Live (TTL) mechanism. The TTL can be modified and removed by you as long as the key has not been removed.
TTL can be set in seconds, milliseconds or Unix time epoch with EXPIREAT
2.1. Strings
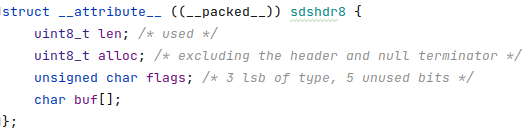
In Redis, strings are called Simple Dynamic String (SDS) → binary safe
https://github.com/antirez/sds

Strings can be manipulated as Text, Float, Integers (manipulate numerical value (INCR and INCRBY)
Commonly used for caching when combined with EXPIRE
ex: Redis checks type of key → If String → check encoding value → If INT → perform INCR
type inventory:4x100m-womens-final #string
object encoding inventory:4x100m-womens-final #int
Commands


2.2. Lists
The advantage of the Redis list getting implemented as a linked list rather than an array list is because Redis list as a data type was designed to have faster writes than reads
Lists of strings, sorted by insertion order, duplicates are allowed
Single level -> No concept of nesting hierarchies or graphs within data structures
max length of a list is 2^32 - 1 elements

Use case scenario
List provides with a sematic interface to store data sequentially in a Redis server where the write speeds are more desirable than read performance. For example, log messages
Pub/Sub scenario: inter process communication
Commands
LPUSH, RPUSH, LPOP, RPOP, LLEN, LRANGE, LINDEX
2.3. Sets
Unordered collection of Strings contains no duplicates (Redis SETs use a hash table to keep item2 all strings unique)
Single level -> No concept of nesting hierarchies or graphs within data structures
max length of a set is 2^32 - 1 elements

Commands
SADD
| SCARDS -> cardinality | set |
SMEMBERS retrieve all elements of a set.
SSCAN -> cursor-based, more efficient
SISMEMBER -> check if element exists in set
SREM: remove by value -> return 0 1
SPOP: remove random number of elements (default 1)
SMOVE source destination member: Move member from the set at source to the set at destination
2.4. Hashes
Mutable collections of field-value pairs.
Nested structure -> Redis JSON
Note: Expiration time can only be defined on a Key, not a Field within a Key
It is worth noting that small hashes (i.e., a few elements with small values) are encoded in special way in memory that make them very memory efficient. (listpack)
https://gist.github.com/antirez/66ffab20190ece8a7485bd9accfbc175
https://www.fatalerrors.org/a/redis-source-code-analysis-26-listpack-source-code-analysis.html

Traditionally Redis, as compact representation of hashes, lists, and sorted sets having few elements, used a data structure called ziplist (single heap allocated chunk of memory containing a list of string elements)
From Redis 5.0, listpack is used as a substitution of ziplist → guarantees the same function as ziplist and avoids cascading updates (ziplist inserting or deleting elements in the middle, while using this particular encoding, may have a cascading effect, where the previous length and even the number of bytes the previous length is encoded, may change and may cascade to the next elements. This was the main source of complexity of ziplist)

Use cases scenario
store simple and complex data objects (ex: session cache) in the Redis server. For example, user profile, product catalogue, and so on
Commands
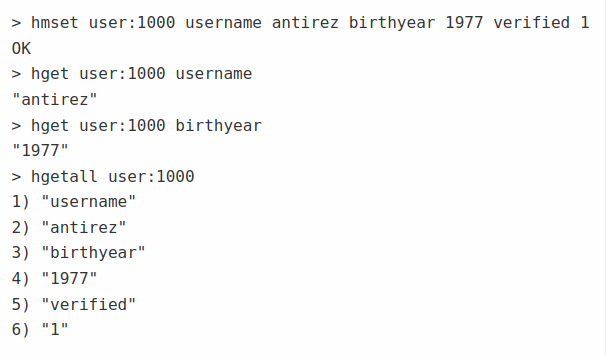
HSET creates and updates a hash
HGET retrieves selected fields
HGETALL retrieves all fields (O(n))
HSCAN is more efficient the HGETALL
HDEL deltes fields within the hash
HINCRBY increments a number stored at a field (There is no HDECRBY command)
HEXISTS return 1 if the field exists and vice versa
HKEYS will return all the field names.
HLEN will return the cardinality (or number of fields) of the hash.
HVALS returns the values associated with each field.
2.5. Sorted Sets
Similar to Set. The difference is that every member of a Sorted Set is associated with a floating point score to order the set, from the smallest to the greatest score. While members are unique, scores may be repeated.
If two elements have the same score the tie is broken by the lexical order of the elements
Internally, Sorted Sets are implemented as two separate data structures:
A skip list with a hash table. A skip list is a data structure that allows fast search linked list within an ordered sequence of elements.
A ziplist, based on the zset-max-ziplist-entries and zset-max-ziplist-value configurations.

Commands
ZADD
ZREM -> remove by value of element
- ZREMRANGEBYLEX
-
ZREMRANGEBYRANK
: remove the range specified - ZREMRANGEBYSCORE
ZINCRBY -> increment the score of an element
ZRANGE, ZREVRANGE [WITHSCORES]-> traverse Low2High, High2Low respectively
ZRANK, ZREVRANK -> get rank of an element
ZSCORE -> get score of an element
ZCOUNT
ZRANGEBYSCORE -> return elements between min and max score
2.6. Bitmaps

Sequence of bits where each bit can store 0 or 1
Bitmaps are memory efficient, support fast data lookups, and can store up to 2 32 bits (more than 4 billion bits)
Not a real datatype, underthehood Bitmap is a string
Use bit operations onto a String
use cases
to store boolean information of a extremely large domain into (relatively) small space while retaining decent performance.
2.7. HyperLogLog
Probabilistic data structure used in order to count unique things (technically this is referred to estimating the cardinality of a set) ⇒ All about efficient counting
⇒ Trade memory for precision: you end with an estimated measure with a standard error, which in the case of the Redis implementation is less than 1%
HyperLogLog is space efficient — the maximum size of the data structure is about 12kb per key
Use cases
When you want to count a very large set that you dont need to get them back or have a space for perfectly accurate counts.
Counting the number of distinct words that appear in a book
Counting the number of unique users who visited a website
example: HyperLogLog vs Set. Assume a website has an average of 100,000 unique visitors per hour. Each user has UUID (32-byte string)
In order to store all unique visitors, a Redis key is created for every hour of a day. This means that in a day, there are 24 keys, and in a month there are 720 keys (24 * 30)

Commands
PFADD → Add element to the count
PFCOUNT → retrieve the current approximation of the unique elements added
PFMERGE → Merge multiple HyperLogLog values into an unique value
Fun fact: Prefix “PF” was named after Philippe Flajolet, the author of the algorithm
2.7. Why Redis single threaded?
https://redis.io/topics/faq#redis-is-single-threaded-how-can-i-exploit-multiple-cpu–cores
Redis is single threaded, which means that it always executes one command at a time, commands are atomic.
- Why single thread?
Avoiding Multi-Threading Overhead (context switching, locking, race conditions, deadlocks, memory barriers, cache invalidations…)
Redis operations are cheap (mostly O(1) time complexity) → Redis is memory, IO bound, not CPU bound
- Better CPU cache locality
- a multi-threaded Redis would suffer from CPU cache invalidations as different cores modify shared data structures (cache line ping-ponging)
- Redis keeps hot data in 1 CPU core’s cache for fast access
Simplicity, easier to reason about code, correctness
- Redis 8 = Targeted Threading Only for I/O
- Redis adds threading where safe: I/O operations like socket read/write + parsing, RDB/AOF loading and saving
- Core command execution still single-threaded to protect main data structures.
- Redis vs Valkey threading design?
- Redis uses one global keyspace accessed by one thread. This gives perfect cache locality, but prevents multi-core scaling.
- Valkey breaks the global keyspace into independent shards (like sharding), mapped to CPU core(s) eliminates the shared structures in Redis -> parallelism with no interference.
3. Redis persistence
if a Redis instance is shut down, crashes, or needs to be rebooted, all of the stored data will be lost. To solve this problem, Redis provides two mechanisms to deal with persistence: Redis Database (RDB) and Append-only File (AOF)
| Persistence Type | What it stores | How it stores |
|---|---|---|
| RDB (Redis Database Backup) | Periodic full snapshots of the dataset | Forks a child process → child writes the entire dataset to a binary dump file (dump.rdb) |
| AOF (Append-Only File) | Every write command executed by Redis | Appends each write command to a log file (appendonly.aof) |
3.1. RDB (Redis Database)
Redis database file (RDB) is an option where the Redis server persists the dataset at regular interval or in other words, snapshots the data in memory at regular intervals.
.rdb file is a binary representing the data stored in a Redis instance
.rdb is optimized for fast reads and writes (internal representation ~ Redis in memory representation)
Can be configed inside redis.conf
.rdb uses LZF compression to make an RDB file very compact
It allows to save an RDB file every hour, day, …
rdbchecksum, rdbcompression, dbfilename, dir, save, …
Internal work
- Redis forks a child process.
- The child copies the in-memory dataset and writes it (in a nonblocking manner) to a single file (dump.rdb) ~ (BGSAVE command).
Drawbacks
- Chances of data loss when Redis crash between 2 snapshots
-
Copy-on-write (CoW) memory cost (extra RAM during snapshot)
- CoW: child and parent share same memory pages until one modifies -> OS creates a copy
- For large datasets with frequent writes, CoW memory can be significant
Use cases
Stateless data → E.g: the data that website records the URLs the user visits in a browsing session to give better service.
E.g: stateful data is unappropriate → data stored is START , PAUSE , RESUME , and STOP . In this case, if we were to lose data such as PAUSE or RESUME during snapshotting, then it might bring the entire system to an unstable mode.
Another use case would be caching engine where there will be fewer data writes than data reads
3.2. AOF (Append-only file)
How AOF works
- Every write command is appended to the AOF buffer → rebuild to correct state
- Redis flushes the buffer to the OS and fsyncs based on configuration.
- Periodically, a rewrite occurs to compress the AOF:
- Fork child → child rebuilds AOF to a minimal sequence of commands.
- AOF
fsyncpolicies:
| Setting | Behavior | Safety | Performance |
|---|---|---|---|
| always | fsync every write | Most safe | Slowest |
| everysec (default) | fsync once per second | Lose ≤1s of data | Good |
| no | OS decides when to flush | Risky | Fastest |
Drawbacks
- Although AOF is more durable than RDB, it is also larger in size and slower to load.
- Higher write overhead than RDB snapshot
Use cases
- Useful for data that have states (e.g: workflow data)
3.3. RDB vs AOF
Restoring data from an RDB is faster than AOF when recovering a big dataset. This is because an RDB does not need to re-execute every change made in the entire database; it only needs to load the data that was previously stored.
-
Although RDB and AOF are different strategies, they can be enabled at the same time
- RDB for faster restarts,
- AOF for better durability,
- AOF rewrite that can include an initial RDB image + incremental commands.
4. Partitioning
Partitioning is a general term used to describe the act of breaking up data and distributing it across different hosts. 2 types of partitioning:
Horizontal partitioning: putting different rows into different tables
Vertical partitioning: creating tables with fewer columns and using additional tables to store the remaining columns
In Redis, we can use replicas to optimize reads and remove bottlenecks fromt he master instance → sometimes not enough:
- The total data to be stored is larger than the total memory available in a Redis server
- The network bandwidth is not enough to handle all of the traffic
In the context of Redis,
Horizontal partitioning ~ distributing keys across different Redis instances (e.g: given 2 sets, distribute each key to different instance)
Vertical partitioning ~ means distributing key values across different Redis instances (e.g: given 2 sets, distribute some values of each set to different instance)
4.1. Range partitioning
Data is distributed based on a range of keys (e.g: Given user:1 → user:3000, user:3001 → user:5000)
Drawbacks
Uneven distribution (e.g: if you decide to distribute the keys based on their first letter but you do not have a good distribution of key names)
Adding or removing a host will invalidate a good portion of data
4.2. Hash partitioning
Does not have “uneven distribution” of range partitioning
It consists of finding the instance to send the commands by applying a hash function to the Redis key, dividing this hash value by the number of Redis instances available, and using the remainder of that division as the instance inde
4.3. Hash slot, consistent hashing
Redis Cluster uses hash slots to split the key space into 16,384 slots. Each key is hashed to one of these slots using the CRC16 algorithm, and each slot is assigned to a specific node in the cluster.
Consistent hashing, in our context, is a kind of hashing that remaps only a small portion of the data to different servers when the list of Redis servers is changed (only K/n keys are remapped, where K is the number of keys and n is the number of servers).

redis> SET mykey1 "Hello"
"OK"
redis> SET mykey2 "Hello 2"
"OK"
redis> CLUSTER KEYSLOT mykey1
(integer) 650
redis> CLUSTER KEYSLOT mykey2
(integer) 8734
-
CROSSLOTerror when accessing multiple keys in different slots - You can control
CROSSLOTerror by using hash tags to control key distribution (e.g:user:{1000}:followers,user:{1000}:followingwill be stored in the same hash slot)
References
Learning Redis → Redis data structure, use cases, persistence handling
Redis in action →data structure, redis web app use cases
Redis Essentials → Common pitfalls, security technique, redis cluster and sentinel
https://redis.io/topics/data-types-intro
https://gist.github.com/antirez/66ffab20190ece8a7485bd9accfbc175
https://www.fatalerrors.org/a/redis-source-code-analysis-26-listpack-source-code-analysis.html
The Engineering wisdom behind redis design
Slide: https://docs.google.com/presentation/d/1CsY9Ifd8GPwPh2d-ah0OeYrn4LTM8nW0Q84CcrANx0Y/edit#slide=id.p
Leave a Comment